728x90
반응형
http://books.toscrape.com/catalogue/category/books/travel_2/index.html
Travel | Books to Scrape - Sandbox
£56.88 In stock
books.toscrape.com

해당 페이지의 책 제목들을 들고와보자.
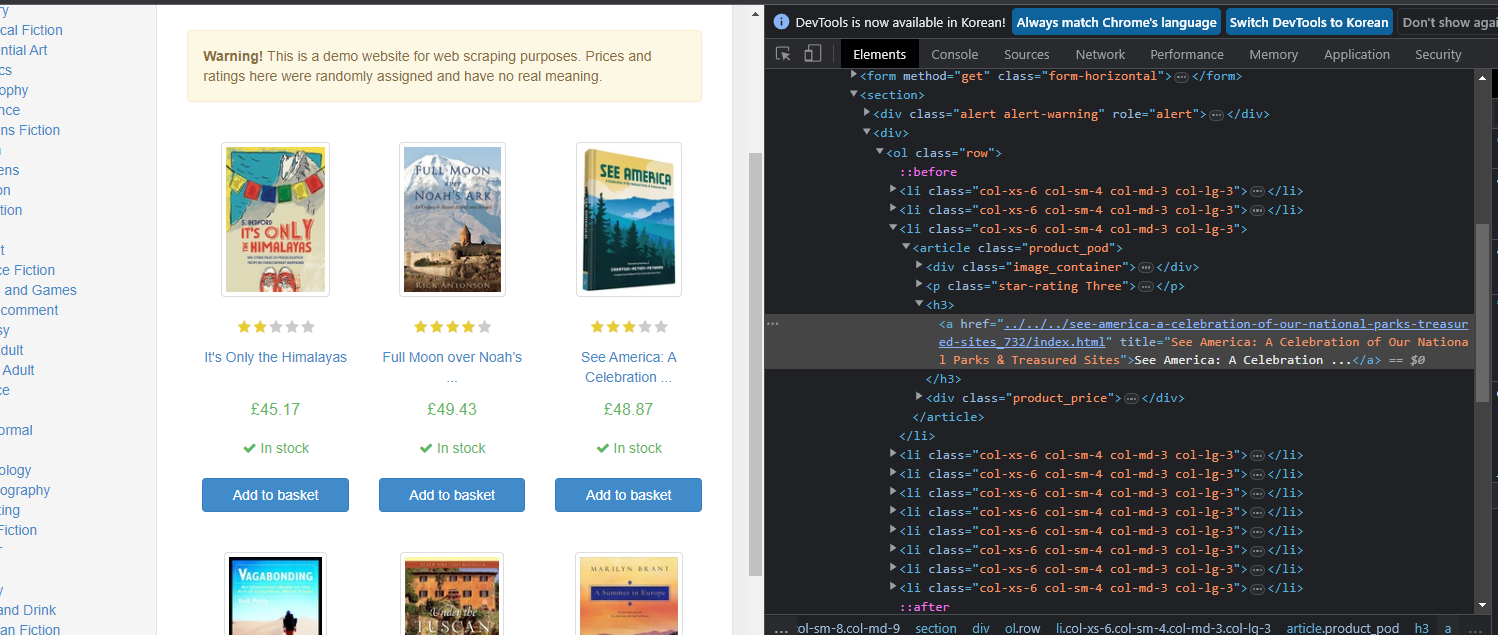
a태그 위의 h3태그로 감싸져있는 것을 볼 수 있다.
1 2 3 4 5 6 7 | from bs4 import BeautifulSoup from urllib.request import urlopen html = urlopen('http://books.toscrape.com/catalogue/category/books/travel_2/index.html') bs = BeautifulSoup(html.read(), 'html.parser') h3 = spanTagList = bs.find_all('h3') for h in h3 : print(h.get_text()) | cs |
이러면 끝난다..
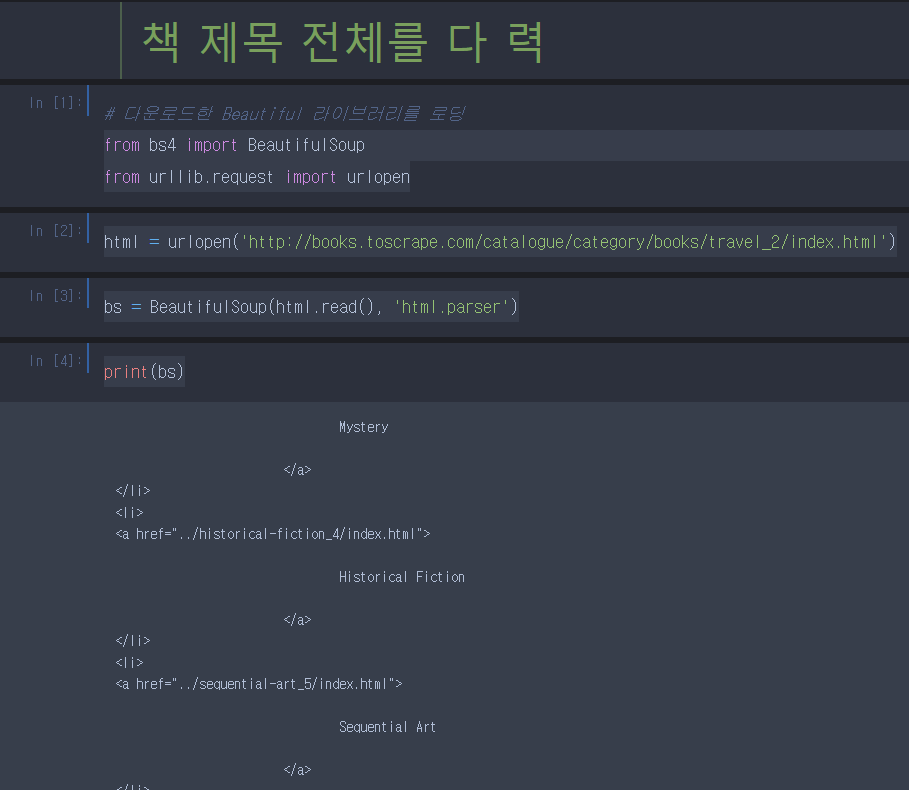

find_all 을하면 List의 형태로 태그들을 가지고 와준다.

따라서 이렇게 for 문에서 반복시켜주면서 한줄 한줄 데이터를 뽑을 수 있다.
728x90
반응형
'✨ python > 크롤링(Crawling)' 카테고리의 다른 글
| 파이썬(python) - 웹크롤링, Selenium (0) | 2023.05.15 |
|---|---|
| 파이썬(python) - 네이버 뉴스 제목 가져오기 (크롤링) (0) | 2023.05.12 |
| 파이썬(python) - 크롤링(Crawling) 또는 스크래핑(Scraping) (0) | 2023.05.11 |



댓글