728x90
반응형
https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105
IT/과학 : 네이버 뉴스
모바일, 인터넷, SNS, 통신 등 IT/과학 분야 뉴스 제공
news.naver.com

나는 이 네이버 뉴스에서 헤드라인 뉴스를 가지고 오려고 한다.

F12를 눌러 태그가 어디에 싸여져 있는지 알아봤는데, a태그의 sh_text_headline 에 쌓여져 있는걸 확인할 수 있다.

a태그만 조회해봤는데, 양이 엄청났다.

a태그의 텍스트만 조회했는데도 여전히 많다.

이렇게 a에 포함된 클래스를 함께 주기 위해서는 class_ 를 사용할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 | from bs4 import BeautifulSoup from urllib.request import urlopen html = urlopen('https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105') bs = BeautifulSoup(html.read(), 'html.parser') bs.find_all('a') a = bs.find_all('a') for s in a: print(s.get_text()) div = bs.find_all('a', class_='sh_text_headline') for d in div: print(d.get_text()) | cs |
위에서부터 천천히 살펴보자.
1. 헤드라인 뉴스와 나머지 뉴스를 모두 포함한 Div 태그 선택


2.
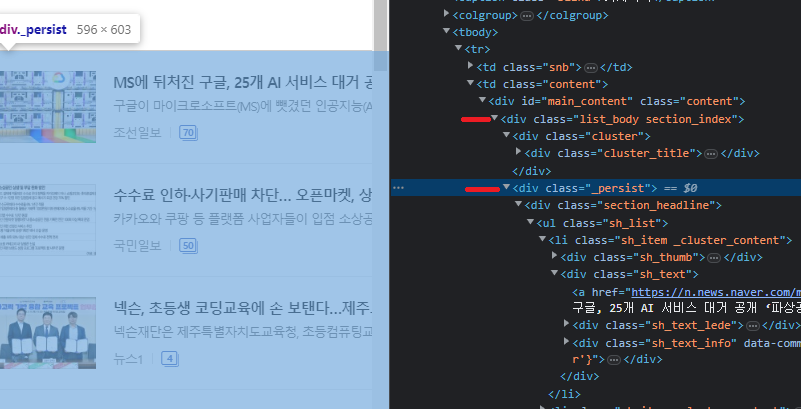





이렇게도 출력될 수 있고, list에 저장해서 언제든지 하나씩 뽑아서 쓸 수도 있다.
728x90
반응형
'✨ python > 크롤링(Crawling)' 카테고리의 다른 글
| 파이썬(python) - 웹크롤링, Selenium (0) | 2023.05.15 |
|---|---|
| 파이썬(python) - 크롤링(Crawling) 또는 스크래핑(Scraping) - 2 (0) | 2023.05.11 |
| 파이썬(python) - 크롤링(Crawling) 또는 스크래핑(Scraping) (0) | 2023.05.11 |



댓글